
一文读懂字符编码:ASCII、Unicode 和 UTF-8
在计算机科学中,字符编码(Character Encoding) 是将人类可读的字符(如字母、数字、符号、汉字等)转换为计算机可以处理的二进制数据的一套规则。在不同的历史阶段和应用场景中,出现了多种字符编码标准,其中最著名的三种是:
本文将带你全面了解这三种编码的发展历程、基本原理以及它们之间的关系与区别。
一、ASCII:计算机世界的第一个字符集 1. 背景
计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)诞生于上世纪60年代,是最早用于表示字符的标准之一。
它主要用于早期的英文打字机和电传设备,在计算机发展初期被广泛采用。
ASCII 表 | 菜鸟教程
2. 特点 3. 示例 字符ASCII 值(十进制)
'A'
65
'B'
66
'0'
48
空格
32
4. 局限性 二、Unicode:统一所有语言的字符编码方案 1. 背景
英语用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0--127表示的符号是一样的,不一样的只是128--255的这一段。
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。为什么电子邮件常常出现乱码?就是因为发信人和收信人使用的编码方式不一样。
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
Unicode 当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639表示阿拉伯字母Ain,U+0041表示英语的大写字母A,U+4E25表示汉字严。具体的符号对应表,可以查询unicode.org。
2. 定义
Unicode 是一个字符集(Character Set),它的目标是为世界上每一个字符分配一个唯一的编号(称为 码点 / Code Point),例如:
其中 U+ 表示 Unicode 的十六进制码点。
3. Unicode 本身不规定存储方式
需要注意的是,Unicode 只是一个字符集(字符与码点的映射),并没有规定这些码点如何以字节的形式存储到内存或文件中。这就引出了接下来要讲的 UTF(Unicode Transformation Format) 编码方式。
三、UTF-8:最受欢迎的 Unicode 编码方式 1. 什么是 UTF-8?
UTF-8 是一种变长字符编码格式,属于 Unicode 的实现方式之一。它是目前互联网上最广泛使用的字符编码方式,尤其在 HTML、JSON、XML、Go、Python、JavaScript 等语言和协议中被默认采用。
2. 特点 3. 编码规则简述(简化版) 码点范围(十六进制)字节数编码格式(二进制)
U+0000 - U+007F
0xxxxxxx
U+0080 - U+07FF
110xxxxx 10xxxxxx
U+0800 - U+FFFF
1110xxxx 10xxxxxx 10xxxxxx
U+10000 - U+10FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
4. 示例说明 四、ASCII、Unicode 与 UTF-8 的关系总结 名称类型内容说明
ASCII
字符集
只能表示 128 个英文字符
Unicode
字符集
给每个字符分配唯一码点(Code Point)
UTF-8
编码方式
一种将 Unicode 码点转化为字节流的方式
简单来说:
ASCII 是古老的字符集;Unicode 是现代的字符集;而 UTF-8 是 Unicode 最流行的一种编码方式。
五、为什么 UTF-8 成为了主流? 六、常见误区澄清 正确理解 七、结语
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
字符
ASCII
Unicode
UTF-8
01000001
00000000 01000001
01000001
01001110 00101101
11100100 10111000 10101101
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
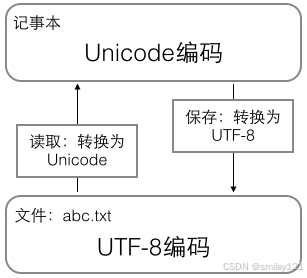
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
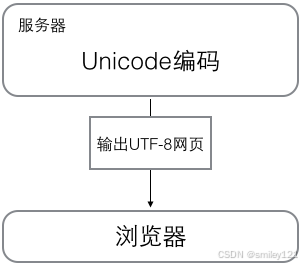
所以你看到很多网页的源码上会有类似的信息,表示该网页正是用的UTF-8编码。
八、参考资料







