
重磅!DeepSeek再开源:视觉即压缩,100个token干翻7000个
【新智元导读】一图胜千言!DeepSeek-OCR模型大胆探索视觉-文本压缩边界。通过少量视觉token解码出10倍以上的文本信息,这款端到端VLM架构不仅在OmniDocBench基准上碾压GOT-OCR2.0,还为LLM的长上下文问题提供高效解决方案。
DeepSeek再发新模型!
Github上,DeepSeek新建了DeepSeek-OCR仓库,目的是探索视觉-文本压缩的边界。
常言道:一图胜万言。对LLM也是如此!
在理论上,DeepSeek-OCR模型初步验证了「上下文光学压缩」的可行性——
从少量视觉token中,模型能够有效解码出超过其数量10倍的文本token。
也就是说,包含文档文本的单张图像,能以远少于等效文本的token量来表征丰富信息。
这表明通过视觉token进行光学压缩可以实现更高的压缩比。
作为连接视觉与语言的中间模态,OCR任务是视觉-文本压缩范式理想的试验场——
它在视觉与文本表征之间建立了天然的压缩-解压缩映射关系,同时提供可量化的评估指标。
在OCR任务上,DeepSeek-OCR有较高实用价值:在OmniDocBench基准测试中,仅用100个视觉token即超越GOT-OCR2.0(每页256token);以少于800个视觉token的表现,优于MinerU2.0(平均每页6000+token)。
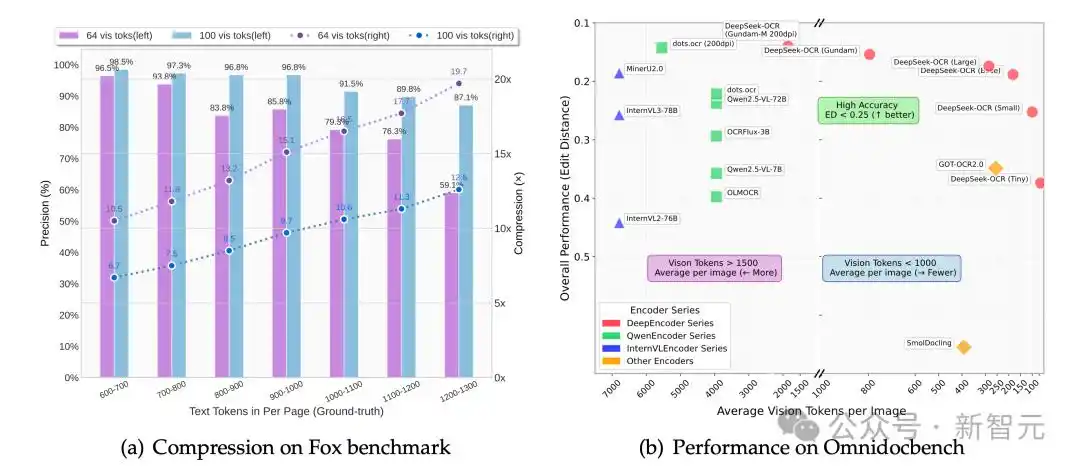
图(a)展示了在Fox基准测试中的压缩比(真实文本token数/模型使用的视觉token数);图(b)展示了在OmniDocBench上的性能对比
在实际应用中,单张A100-40G显卡,可支持每日20万页以上的大语言模型/视觉语言模型训练数据生成。
新模型还能解析图表、化学方程式、简单几何图形和自然图像:
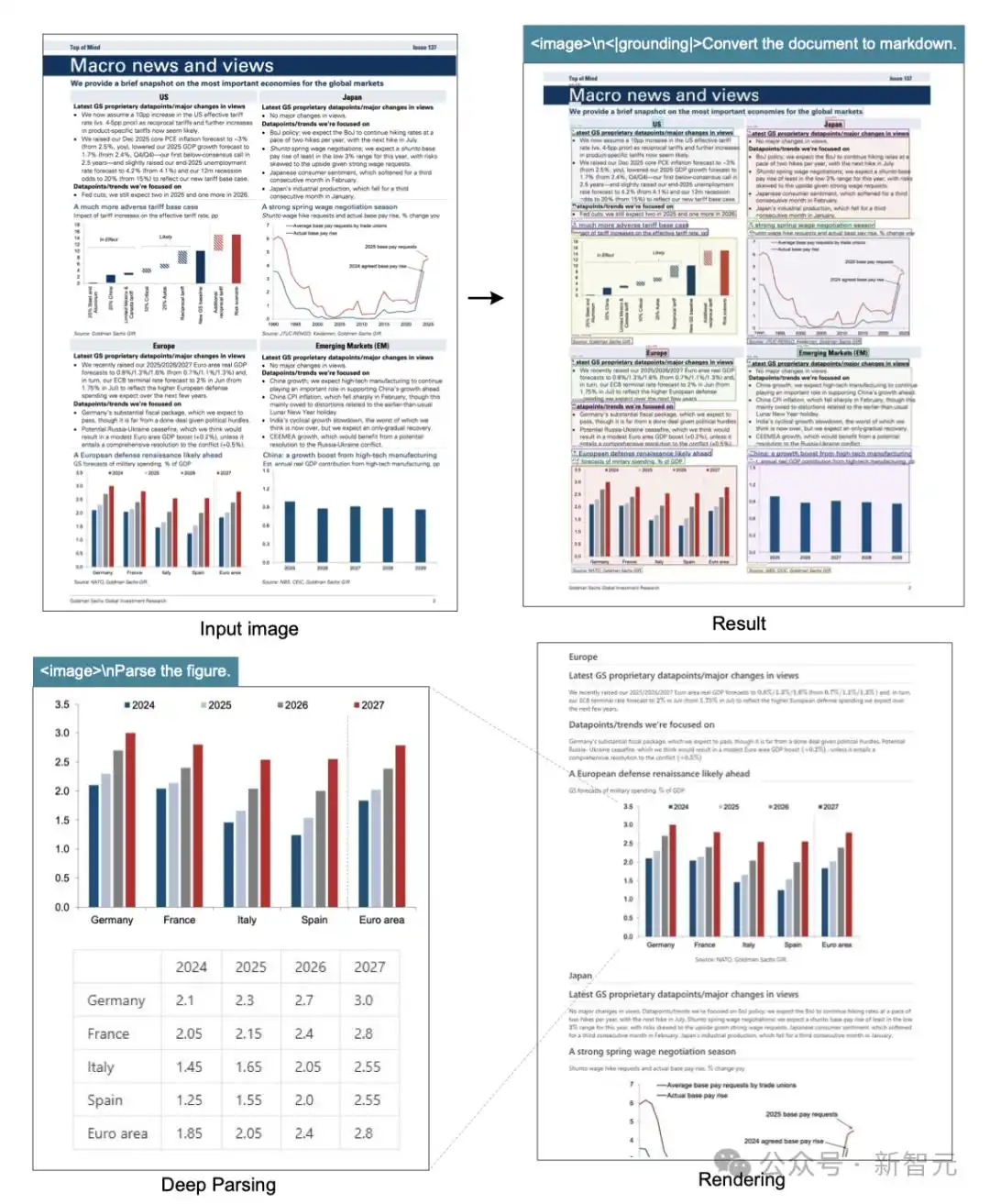


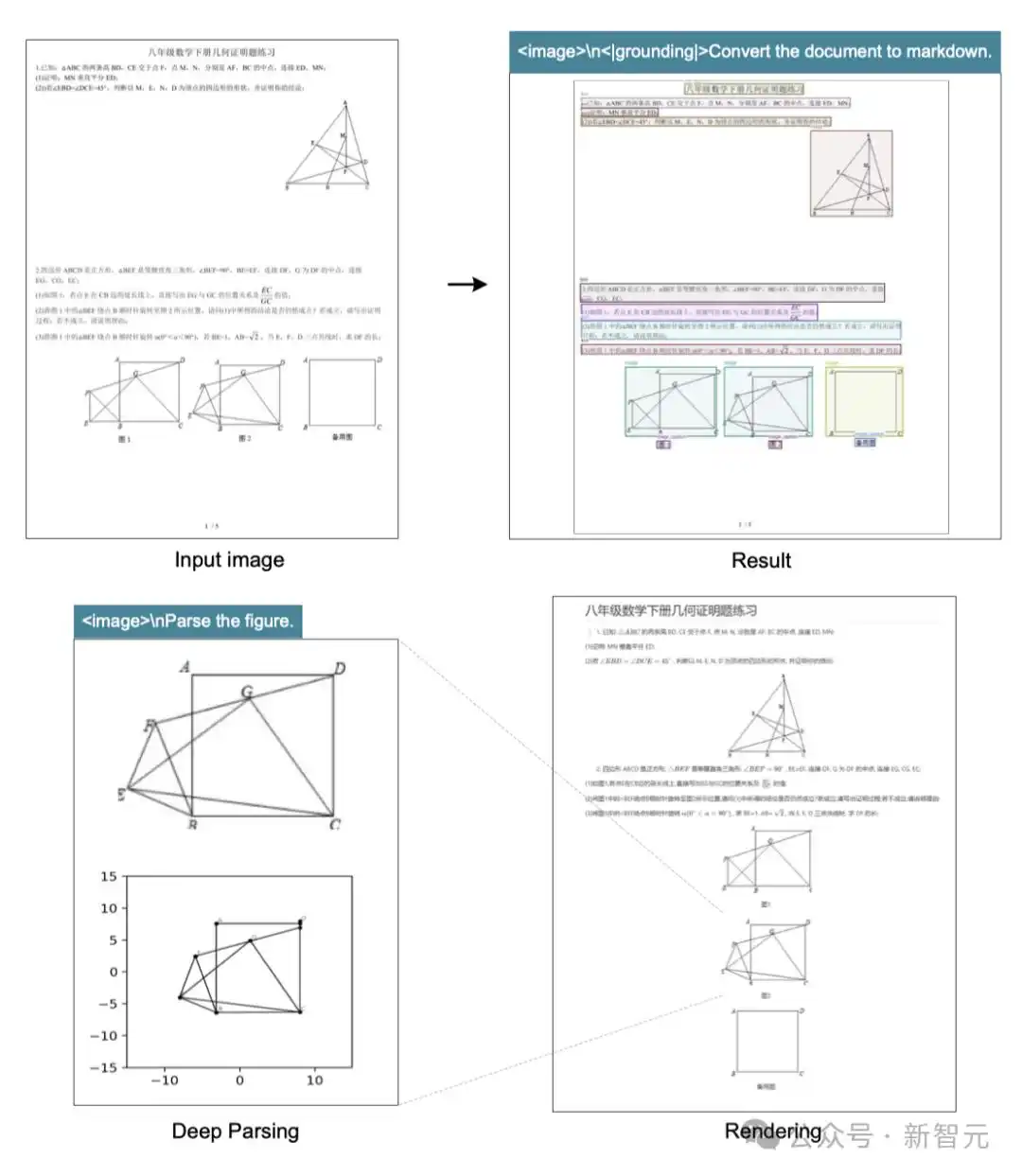
可以上下滚动的图片
在不同历史上下文阶段中,DeepSeek-OCR的视觉-文本压缩可减少7–20 倍的token,为解决大语言模型的长上下文问题提供了可行方向。
这一范式为重新思考视觉与语言模态的协同融合,进而提升大规模文本处理与智能体系统的计算效率,开辟了新的可能。
这一发现将有力推动视觉语言模型与大语言模型的未来发展。
Github:https://github.com/deepseek-ai/DeepSeek-OCR
HuggingFace:https://huggingface.co/deepseek-ai/DeepSeek-OCR
开源神器DeepSeek-OCR
探索上下文光学压缩
当前开源VLM(视觉语言模型)采用了三种主要的视觉编码器架构,但各有各的缺陷。
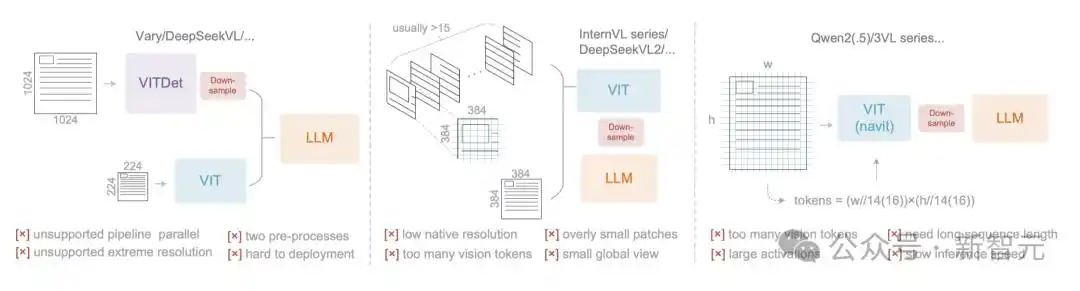
随着VLM的进步,许多端到端的OCR模型应运而生,根本性地改变了传统的管道架构,简化了OCR系统。
但有个核心问题:
对于一个包含1000个字的文档,至少需要多少个视觉token来解码?
这个问题对于研究「一画胜千言」的原则具有重要意义。
DeepSeek-OCR意在回答这一问题。它采用统一的端到端VLM架构,由编码器和解码器组成。
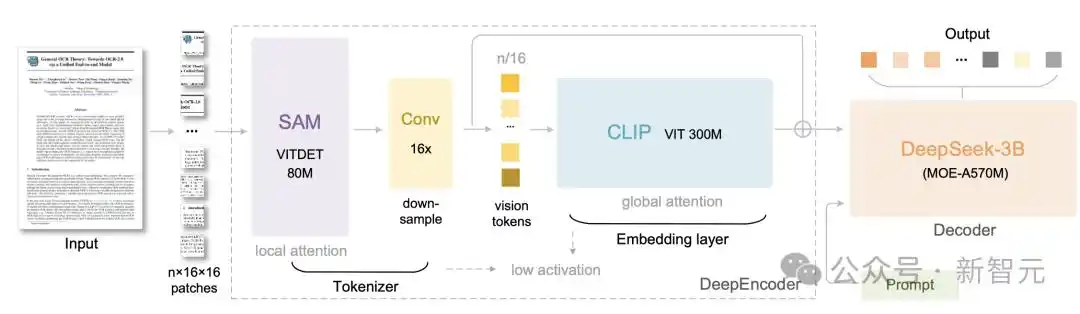
编码器(即DeepEncoder)负责提取图像特征,并对视觉表示进行token化与压缩处理。解码器则根据图像token和提示信息生成所需结果。
编码器:DeepEncoder创新架构
为了验证「上下文光学压缩」(context optical compression)的可行性,视觉编码器需要满足以下特性:
能处理高分辨率图像;
在高分辨率下保持较低的激活开销;
生成较少的视觉token;
支持多分辨率输入;
参数规模适中。
研究者提出了全新的视觉编码器DeepEncoder。DeepEncoder参数量约为3.8亿,主要由串联连接的SAM-base和CLIP-large构成。
视觉感知特征提取器,主要使用窗口注意力(window attention), 主架构为8000万参数的SAM-base(patch-size 16);
视觉知识特征提取器,采用密集全局注意力(dense global attention),主架构为3亿参数CLIP-large 。
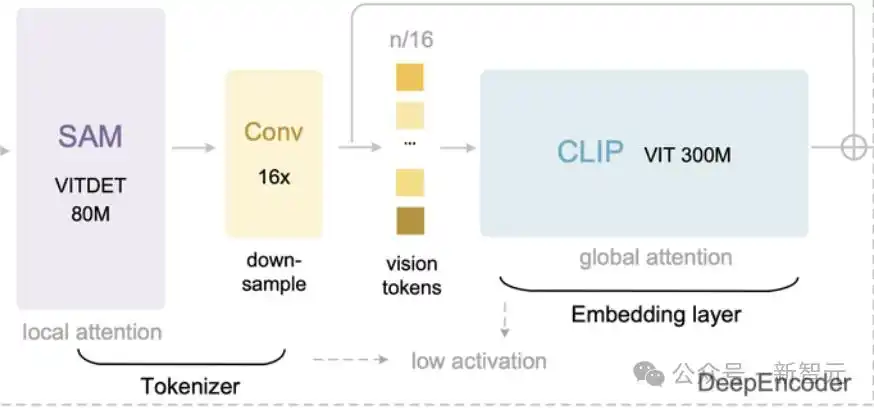
在这两个组件之间是一个2层卷积模块,对视觉token进行16×下采样。
DeepEncoder会压缩图像打下,比如将输入大小为1024×1024的图像划分为1024/16×1024/16=4096个patch token。
编码器的前半部分由窗口注意力主导且只有80M参数,因此激活内存消耗是可接受的。
在进入全局注意力模块之前,4096个token通过压缩模块,最终token数量会减为4096/16=256,从而使得整体的激活内存消耗可控。
假设有一张包含1000个光学字符的图像,要想测试解码需要多少个视觉token,就要求模型能够支持可变数量的视觉token。
也就是说,DeepEncoder需要支持多种分辨率。
动态插值位置编码可满足上述需求。
研究者设计了多个分辨率模式,以便在模型训练过程中同时支持多种分辨率,从而实现单个 DeepSeek-OCR 模型支持多个分辨率的能力。
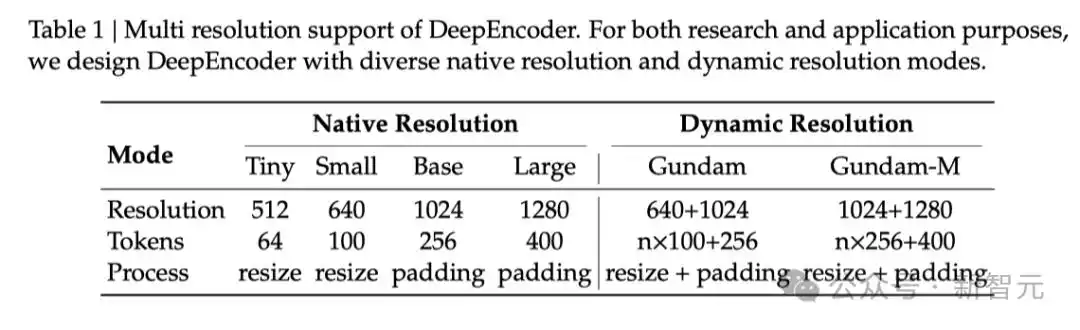
如下图4所示,DeepEncoder主要支持两种输入模式:原生分辨率和动态分辨率。每种模式下又包含多个子模式。

原生分辨率支持四种子模式:Tiny、Small、Base和Large。
动态分辨率由两种原生分辨率组合而成。
支持动态分辨率主要是为了应对超高分辨率输入(例如报纸图像)的应用需求。瓦片化(tiling)是一种二级窗口注意力方法,可以进一步有效减少激活内存消耗。
在Gundam模式下,DeepEncoder输出的视觉token数量为n×100+256,其中n为瓦片的数量
Gundam模式与四种原生分辨率模式一起训练,以实现一个模型支持多种分辨率的目标。
值得注意的是,Gundam-master模式(1024×1024的局部视图+1280×1280 的全局视图)是通过在已训练的DeepSeek-OCR模型上继续训练得到的。
下表1总结了各模式下的分辨率和token数。
解码器:DeepSeek-3B-MoE
解码器使用DeepSeekMoE,具体为DeepSeek-3B-MoE。
在推理过程中,该模型激活了6个路由专家和2个共享专家,总计激活了约5.7亿参数。
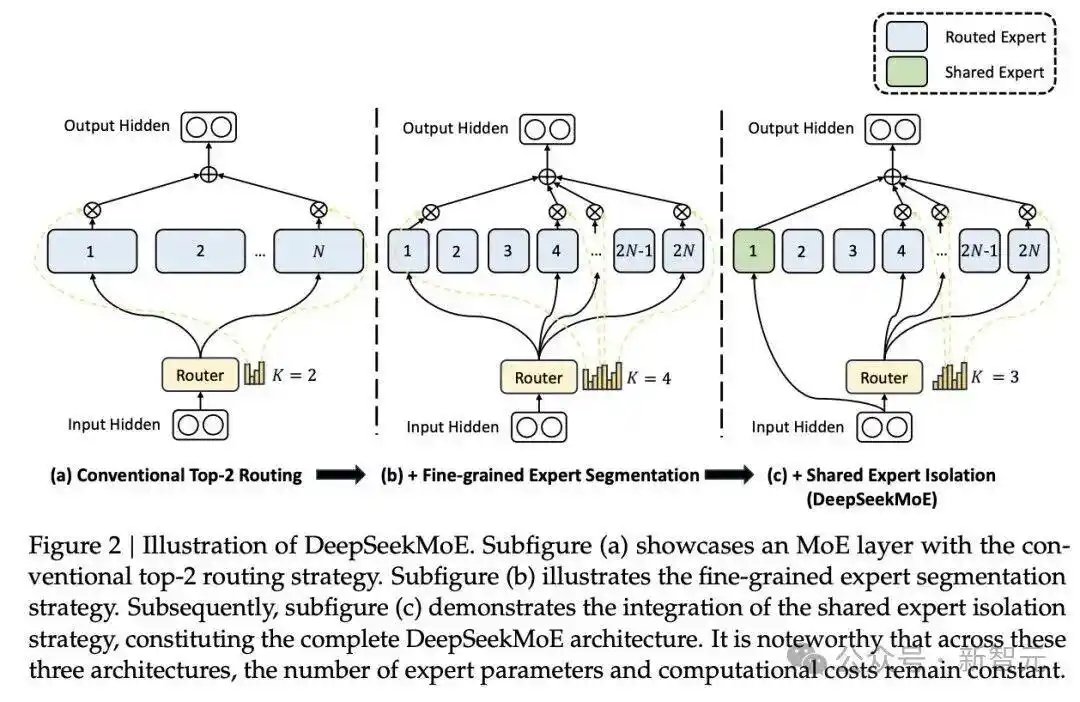
3B的DeepSeekMoE非常适合于以领域为中心的视觉语言模型(VLM)研究——
它能够获得3B模型的表达能力,同时享有类似500M小型模型的推理效率。
具体结果
在Fox基准集,研究者验证 DeepSeek-OCR在文本密集型文档上的压缩与解压能力,初步探索「上下文光学压缩」的可行性与边界。
如下表2所示,在10×压缩比内,模型的解码精度可达约97%,这一结果极具潜力。
而且输出格式仍与Fox基准的格式并不完全一致,因此实际性能可能略高于测试结果。
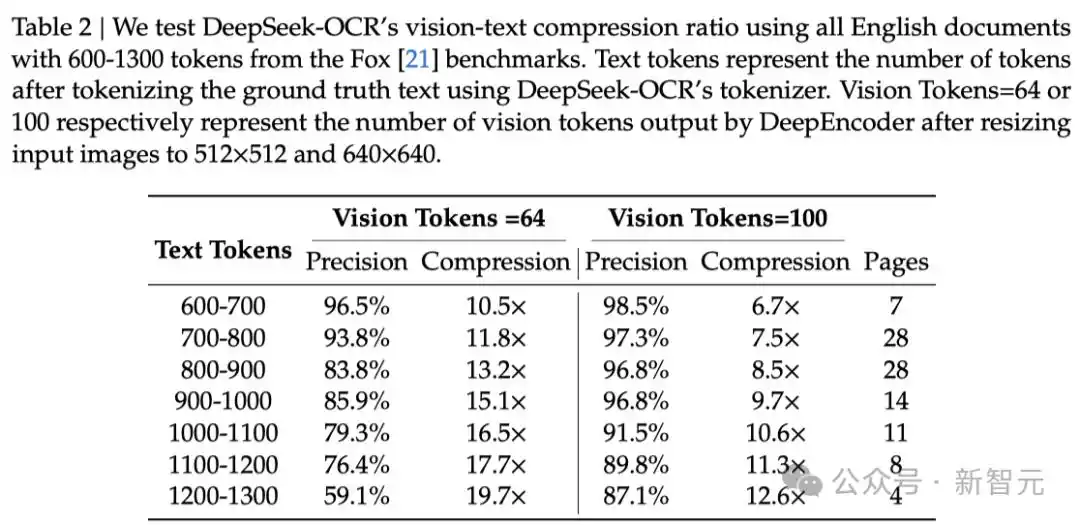
未来,或可通过文本到图像(text-to-image) 方法实现接近10×无损上下文压缩。
当压缩比超过10×时,性能开始下降,原因可能有二:
长文档布局更复杂;
长文本在 512×512 或 640×640 分辨率下出现模糊。
第一个问题可以通过将文本渲染到单页布局来缓解,而第二个问题则可能成为一种 「遗忘机制」(forgetting mechanism)的自然表现。
当压缩比接近20× 时,模型精度仍可维持在60%左右。
这些结果表明,光学上下文压缩(optical contexts compression) 是一种极具前景且值得深入研究的方向。
更重要的是,这种方法不会带来额外的计算开销,因为它能够直接利用VLM基础设施——
多模态系统本身就内置视觉编码器,从而具备天然的支持条件。
DeepSeek-OCR还很实用,能够为LLM/VLM预训练构建数据。
在实际部署中,DeepSeek-OCR使用20个计算节点(每节点配备8张A100-40G GPU)每日可为LLM/VLM生成3300万页训练数据。
为了量化OCR性能,研究者在OmniDocBench上测试了DeepSeek-OCR,结果如表3所示。
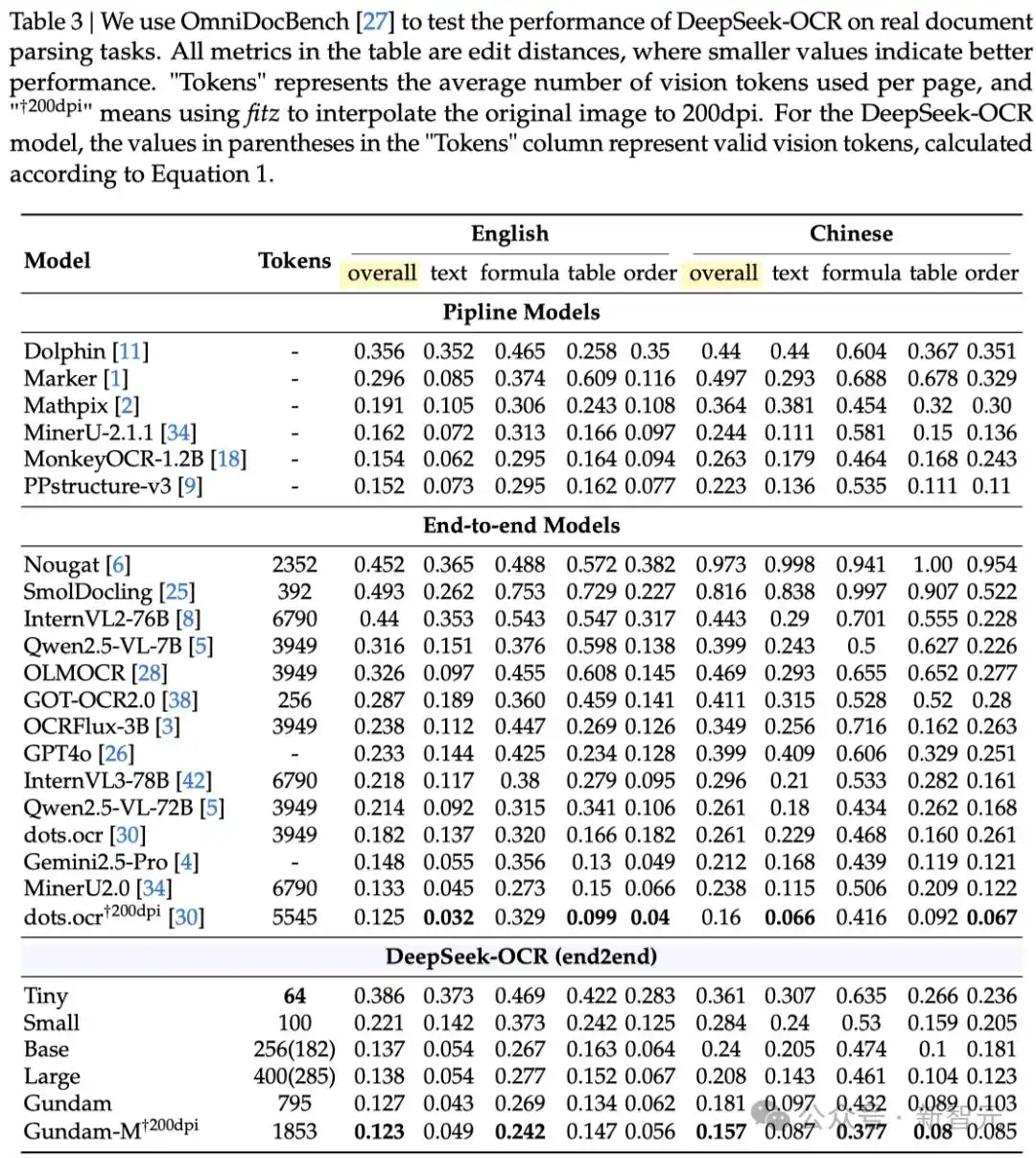
在仅需100个视觉token(640×640分辨率)的情况下,DeepSeek-OCR超越了使用256个token的 GOT-OCR2.0;
在400个token(其中285个有效 token,1280×1280分辨率)的情况下,模型在该基准测试中达到了与现有最先进模型相当的性能;
使用不到800个token(Gundam 模式),DeepSeek-OCR超过了需要近7000个视觉token的MinerU2.0。
这些结果表明,DeepSeek-OCR 在实际应用中非常强大,且由于更高的 token 压缩,模型具有更高的研究上限。
如下表4所示,某些类型的文档,只需要非常少的token即可获得令人满意的性能。
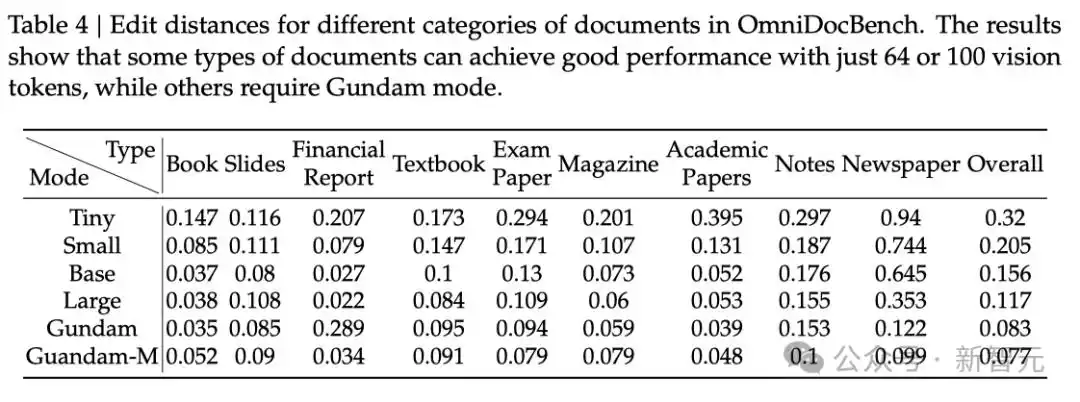
对于书籍和报告类型文档,DeepSeek-OCR仅需100个视觉token即可达到良好的性能。这可能是因为这类文档中的大多数文本token数量在1,000以内,意味着视觉token压缩比不超过10×。
除了解析图表、化学方程式、简单几何图形和自然图像外,对于PDF文档,DeepSeek-OCR可以处理近100种语言。
如下图11所示,DeepSeek-OCR 不仅在常见语言处理上表现出色,而且在多语言处理能力上也具有广泛的适用性,进一步增强了其在全球范围内的应用潜力。

DeepSeek-OCR具有某种程度的通用图像理解能力。
相关的可视化结果如图12所示,展示了该模型在图像描述、物体检测和语境定位(grounding) 等任务中的表现。

详细结果和内容,见下列参考资料。
参考资料:
https://github.com/deepseek-ai/DeepSeek-OCR
https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf







